Real data from a real codebase
This is buildlog running on itself. 40 sessions, 100 logged mistakes, 81 review cycles. Not a demo.
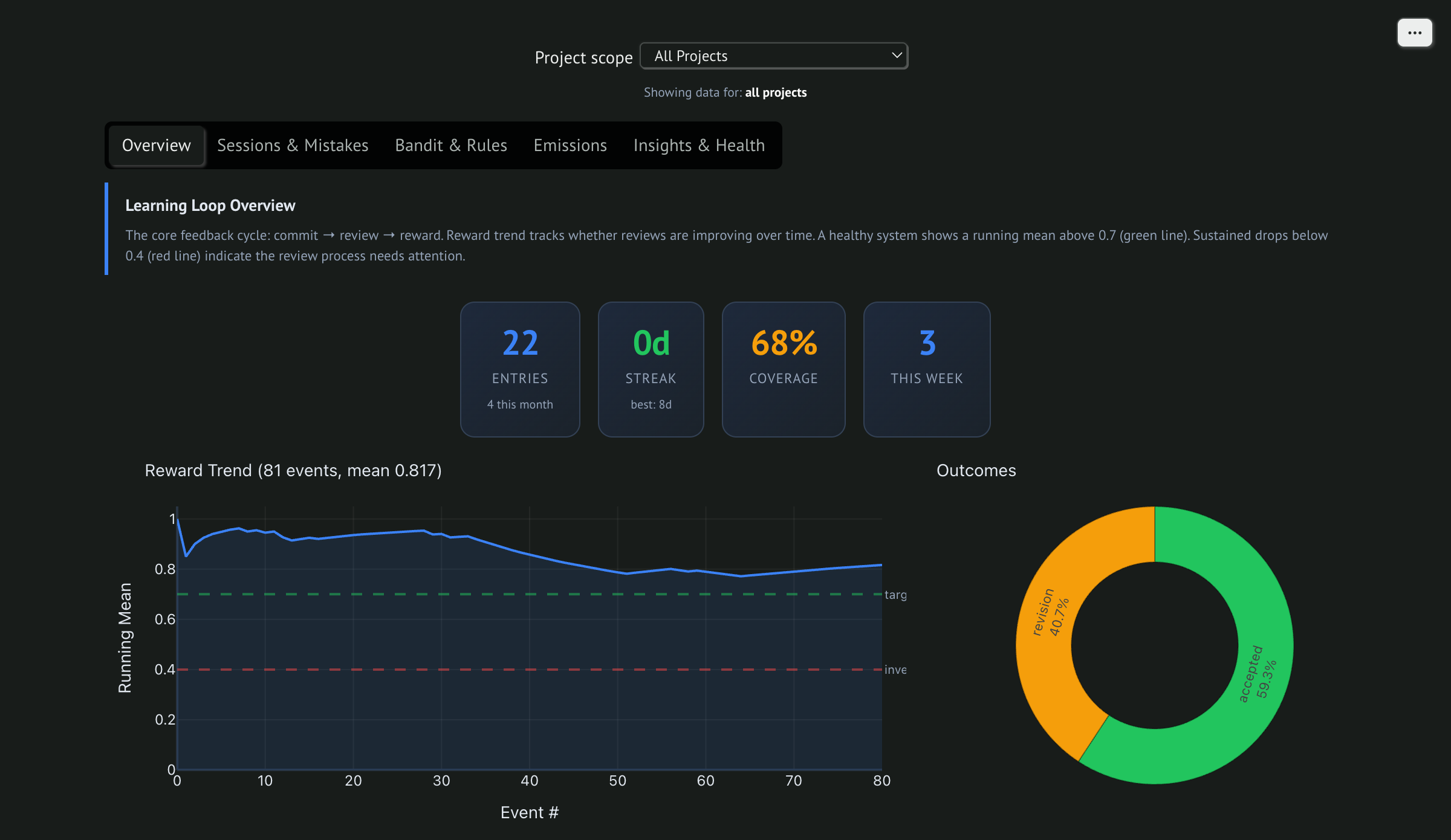
The loop is working
Running reward mean at 0.817 across 81 gauntlet review cycles. 59% accepted on first pass, 41% revised, 0% rejected. The green line is the target. We're above it.
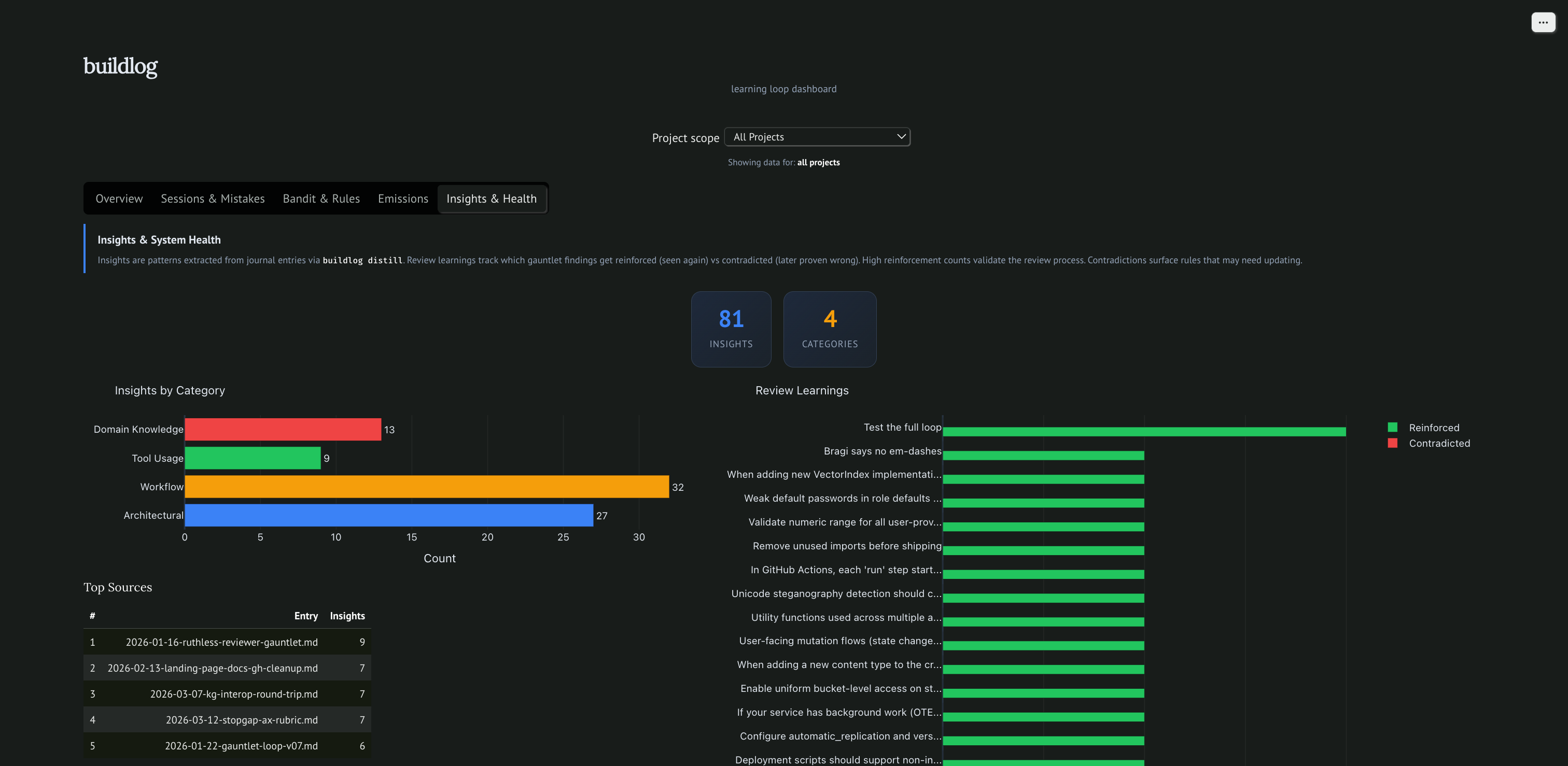
81 patterns extracted, 12 learnings reinforced
Insights by category (architectural, workflow, tool usage, domain knowledge) extracted from journal entries. Review learnings tracked as reinforced or contradicted across sessions.
buildlog viz launches this dashboard locally. Your data, your machine.